Decentralizing the Builder Role

Introduction
I have an addendum to my Hitchhiker’s Guide to Ethereum. Too soon.
Quick recap - a key theme of that report was the idea from Vitalik’s Endgame that all roads seemingly lead to:
Centralized block production
Decentralized & trustless block validation
Censorship is still prevented
PBS seeks to isolate centralization to the builder (away from validators), then Ethereum adds armor (e.g., crList) to mitigate builders’ censorship powers. Builders will naturally be sophisticated, so the open question was mostly just how centralized they’d be. Are we talking 1 builder? 10?
A centralized builder still isn’t ideal though, so can we do better? There are two approaches to this problem:
Decentralized market of many builders - Ensure the builder market is competitive without entrenched parties. Many builders compete and capture only a small margin. The role becomes very commoditized. This requires solving problems like exclusive orderflow which could otherwise entrench a single builder.
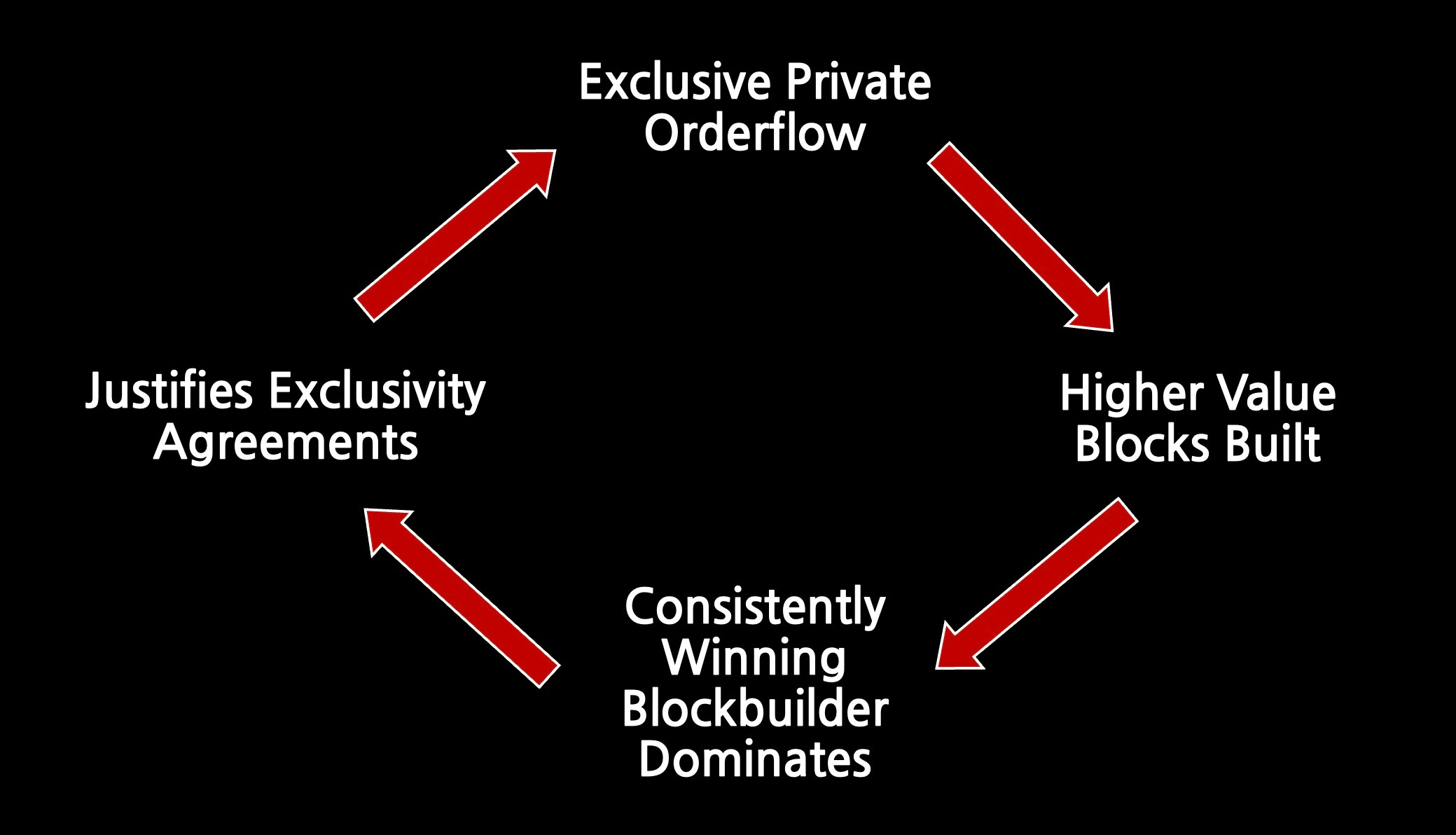
Decentralize the builder role itself - Make the winning builder itself a decentralized protocol. A decentralized set of participants all contribute to building a given block.
This report is largely built around Vitalik’s recent SBC MEV workshop speech. I’ll break it down and offer further analysis.
Can a Decentralized Builder Win?
There are really two underlying questions here:
Technical feasibility - I’ll present some paths which could work (other possibilities exist, and are being actively explored)
Competitiveness - Will users actually want to use it? Or will a centralized builder always outcompete a decentralized one on features and efficiency?
What to Decentralize?
Centralized builders have it easy. The below contemplates some of what could be decentralized for a distributed builder needing to aggregate bundles and transactions across many searchers and users:
Algorithms - Builders run algorithms to aggregate searchers’ bundles and other transactions then fill out the rest of the block themselves. This algorithm and its inputs could be decentralized. (Note that this presupposes the simple case here of only one algorithm being run by the distributed builder. In reality, it may be possible for different participants within the distributed builder to contribute different portions of the block while running different algorithms.)
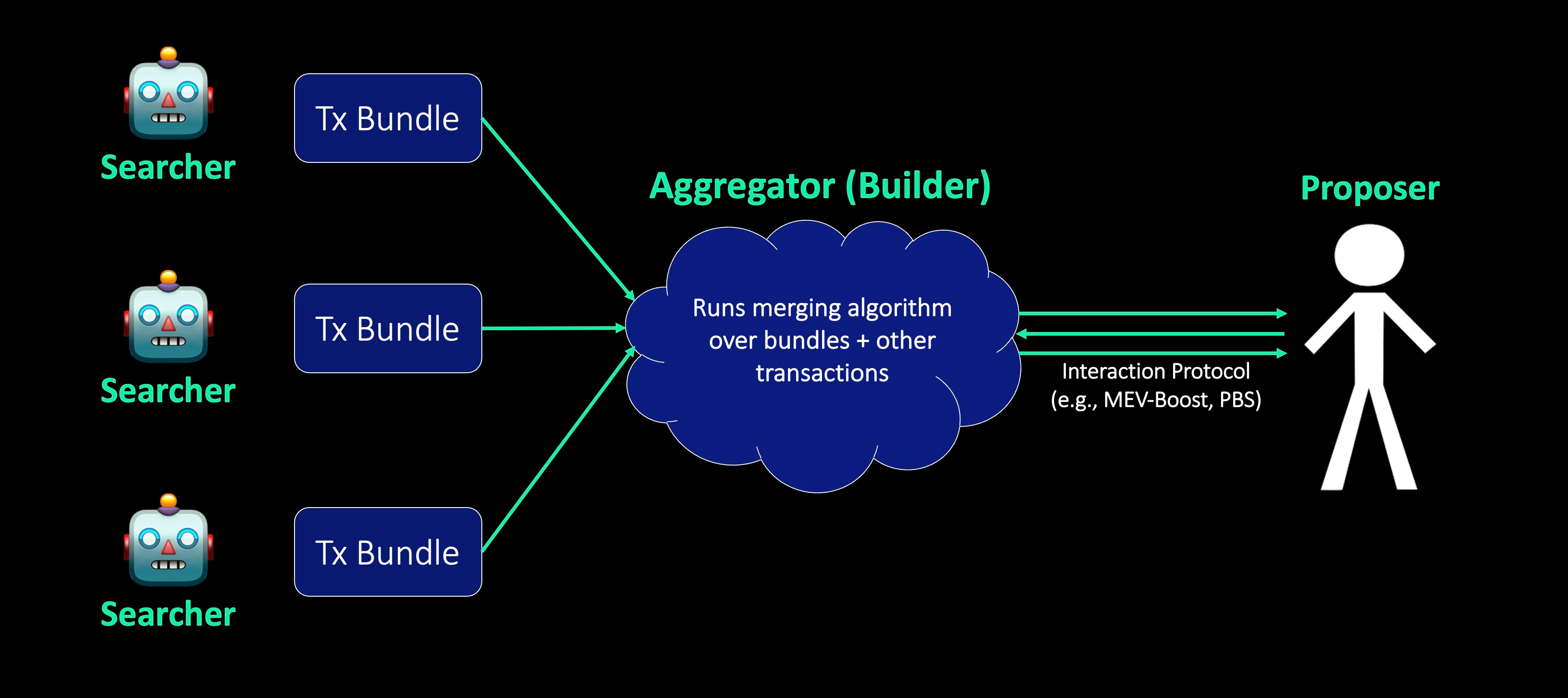
Resources - Resource requirements will increase meaningfully, especially with Danksharding. Blocks will carry more data and be more complex to build → much higher bandwidth and hardware requirements to build them. Instead of requiring one node to build and distribute this entire block, the work could be split between many nodes.
Extra Builder Services - Builders may get creative and offer new services such as transaction pre-confirmations. For distributed builders to be successful, they’ll need to offer services which are competitive with centralized ones.
Access to Orderflow - Sending orderflow to a single builder is pretty straightforward, and can offer benefits to users. Maybe they promise to not frontrun you, and they can backrun you to give you some rebate. Decentralizing access to orderflow across potentially many participants is trickier.
Privacy - Similarly, it’s easiest to trust one builder that your order will be executed privately, so you could send it just to them. Distributed builders need a way to offer transaction privacy while also including many decentralized parties in the process.
Cross-chain Execution - Distributed builders need a way to coordinate with outside actors to capture cross-chain MEV (e.g., only complete swap on chain X if swap on chain Y will be completed atomically).
Challenges
There are several hurdles to overcome if we want to avoid trusted third parties throughout the block production supply chain. Some of the challenges I’ll address here include:
How to protect searchers from MEV-stealing?
If builders see the bundles that searchers submit to them, they can copy the transactions then replace the searchers’ addresses with their own. The builder captures the MEV without rewarding the searchers.
The commit-reveal scheme used in enshrined PBS and MEV-Boost (plus an intermediary trusted relay) removes this same MEV-stealing threat from the proposer ←→ builder relationship, but it’s an unresolved issue for searchers ←→ builders. Searchers currently just trust builders, but trust isn’t a scalable solution.
How to allow the aggregator mechanism to combine searcher inputs?
Protecting searchers from MEV-stealing means their bundles can’t be sent in clear text. But if they're not in the clear how can the builder aggregate them?
How to ensure that the aggregator mechanism can actually publish the block ?
Bundle contents will have to be in the clear eventually. What's the process going from ciphertext → plaintext, and how do we achieve that without trust assumptions?
How to protect searchers against aggregator + proposer collusion?
Note this is not an exhaustive list of challenges in constructing a distributed builder. There are other open questions (e.g., how do you prevent a distributed builder from getting DDOS’d with a flood of bad bundles that they’re forced to simulate?) and unknown unknowns.
Idea 1 - Trusted Hardware
One approach leverages trusted hardware - TPM (Trusted Platform Module). The sequence looks like this:
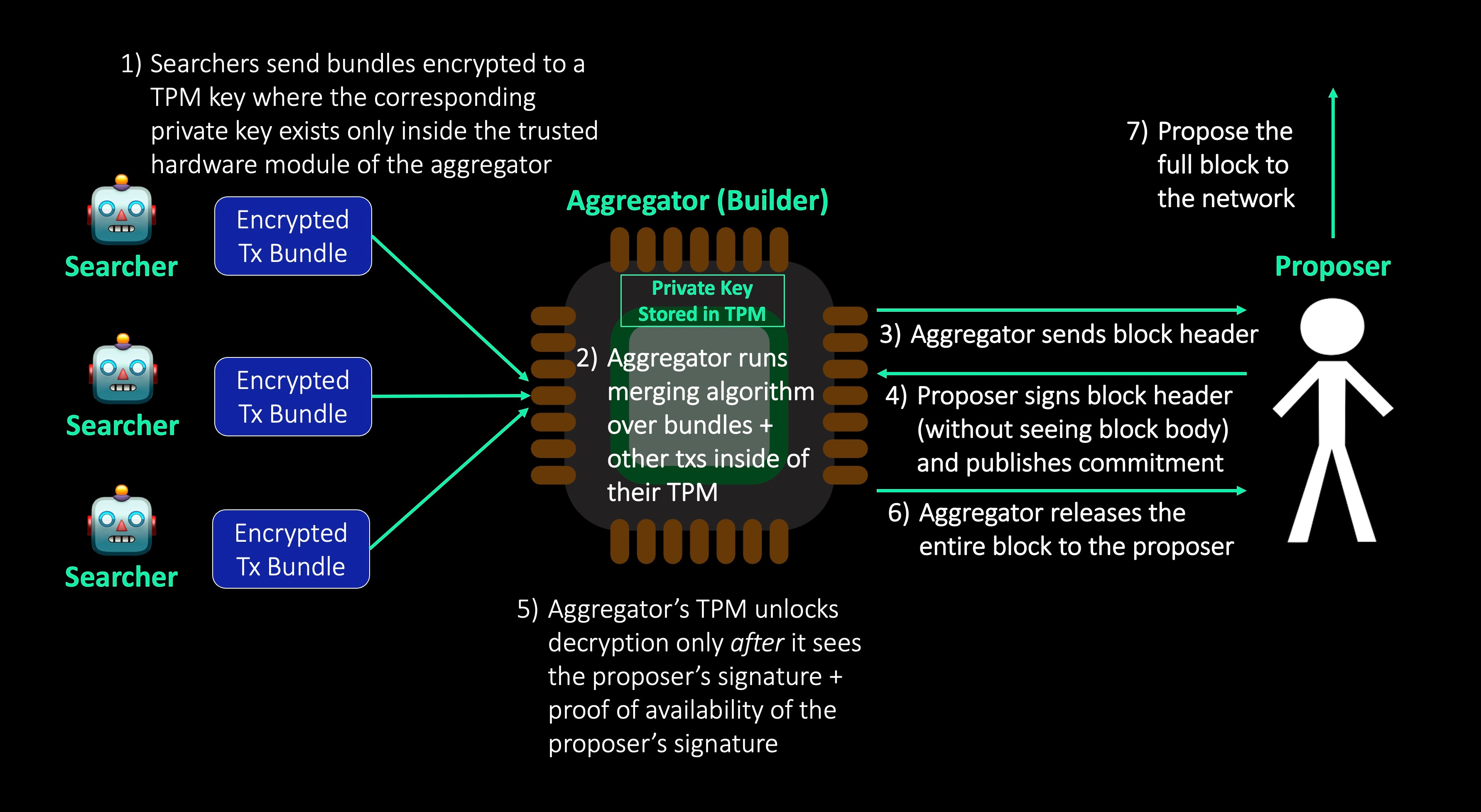
The TPM must be convinced of two things before decrypting the block:
Proposer signature - This commitment to a block header (without seeing the block body) prevents proposers from MEV-stealing. If the proposer tries to steal the MEV for themselves after the builder block body is revealed (by proposing an alternative block), anyone can present their original commitment. This proves the proposer signed two blocks at the same block height → they’re slashed.
Proof of availability of the proposer signature - Protects against aggregator + proposer collusion. It’s not enough that the proposer’s commitment exists - it must be available. If only the aggregator receives the commitment, they could simply hide it forever allowing the proposer to propose an alternative MEV-stealing block. The TPM must be convinced that the original proposer signature was in fact made public.
There are a few ways to achieve proof of availability for the proposer signature:
Attesters - Validators could attest to seeing the proposer signature, then the TPM could check for the proposer and these attester signatures. This requires Ethereum protocol changes.
Low-security real-time data availability oracle - Something like Chainlink could attest to the fact that the signature exists and will be re-broadcasted.
M of N assumption within the aggregator - The aggregator itself could be a distributed M of N protocol. There could be a threshold vote within the aggregator protocol, and you have an honesty assumption for it.
Idea 2 - Merging Disjoint Bundles & Sequential Auctions
Merging Disjoint Bundles
This approach requires the M of N aggregator, but we can get rid of the TPM. The process looks something like this:
Searchers send bundles that are encrypted to a threshold key. The bundles contain an access list (list of what accounts and storage slots they access) and a SNARK of correctness (noting technical complexity to quickly produce this).
Aggregator merges disjoint bundles which maximize the total bid. (We’re only discussing aggregating disjoint bids here, but there are potentially ways to improve on this further.)
Aggregator must compute the state root
That last step is tricky. Computing the state root requires seeing transactions in the clear, or at minimum seeing their state updates. However, even seeing state updates might be enough to conduct MEV-stealing. We have a couple of options for when to compute the state:
Have one aggregator node decrypt then compute the state. However, they can collude with the proposer.
Compute the state root only after the proposer commits to supporting whatever block and state root is received. This setup would leverage EigenLayer - proposers subject themselves to additional slashing conditions to participate. Proposers send an off-chain message committing that the only block they will produce in their turn is one that contains this set of bundles (whatever they are). Only after the proposer makes that commitment do the bundles get decrypted, and the state root gets calculated. If the proposer violates this commitment then they get slashed.
Note it’s also possible to avoid the SNARK requirement mentioned earlier for this EigenLayer construct. The proposer here could pre-commit to an alternative block or alternative block combination which is used if the one presented to them turns out to be invalid. The invalidity of the first block combination can then be checked using a fraud proof.
Sequential Auctions
The EigenLayer technique could be used directly to do disjoint bundle merging, or alternatively it may rely on a multi-round sequential auction within each slot. (Note that the SNARK requirement can also be avoided in this sequential construct as well if desired.)
For example, the following could happen all within a single block:
Round 1
Proposer signs an EigenLayer message pre-agreeing to some transactions (including bundle 1) which maximizes their bid in this round to start the block
Builder reveals this portion of the block
Proposer publishes state diffs
Round 2
Proposer signs an EigenLayer message pre-agreeing to additional transactions (including bundle 2) which maximizes their bid in this round to continue the block
Builder reveals this portion of the block
Proposer publishes state diffs
Round 3…
One downside is that this merging may be suboptimal. For example, the proposer may have pre-agreed to bundle 1, then they receive an even more profitable bundle 2 which conflicts with bundle 1. They would have to reject this bundle 2.
A centralized builder with the same orderflow who sees all transactions could instead include bundle 2 when they build the block at the end of the slot (because they hadn’t pre-agreed to bundle 1).
Another potential downside - sequential auctions could make non-atomic MEV quite difficult as searchers would have no way to cancel or update their bids (once committed to) if the state of the world changes. If you need to commit to a transaction 10+ seconds before it’s included, you can’t take on as much risk as you could if you retain the ability to update your bid.
However, that example assumes equal orderflow. In reality, this distributed builder may be able to outcompete centralized builders in receiving more orderflow because of the guarantees it provides. Better guarantees → more orderflow → most profitable block built (even despite the other downsides). It would then make economic sense for proposers to opt into this construct (cutting themselves off from accepting other builders’ blocks) as the distributed builder consistently provides the highest value blocks.
To be successful, the value provided by the distributed builder would likely need to outweigh the downsides it presents (including less efficient merging and challenges doing non-atomic MEV).
Block Construction Post-Danksharding
Danksharding keeps node requirements low for validators. Individual nodes are only responsible for downloading portions of the block.
However, the initially proposed design would meaningfully increase the hardware and bandwidth requirements to build an Ethereum block (though validators could always reconstruct in a distributed manner). The question then is whether we can even do the initial building in a distributed manner. This would remove the need for a single high-resourced entity to build the full block, compute all the KZG commitments, connect to many subnets to publish it, etc.
(Note: open research question whether this architecture will use subnets or something like a DHT, but I’ll assume subnets here).
It’s actually very possible to build in a distributed manner. Distributed erasure coding isn’t even that hard.
To start, whoever includes each data transaction is responsible for encoding it and propagating the chunks of the blobs to the subnets and the data availability network.
When the aggregator chooses which data transactions to include, they can use a real-time DA oracle. The aggregator can’t just do data availability sampling (DAS) themselves because this isn’t secure when only one party is doing DAS. So some distributed oracle would need to download the whole thing.
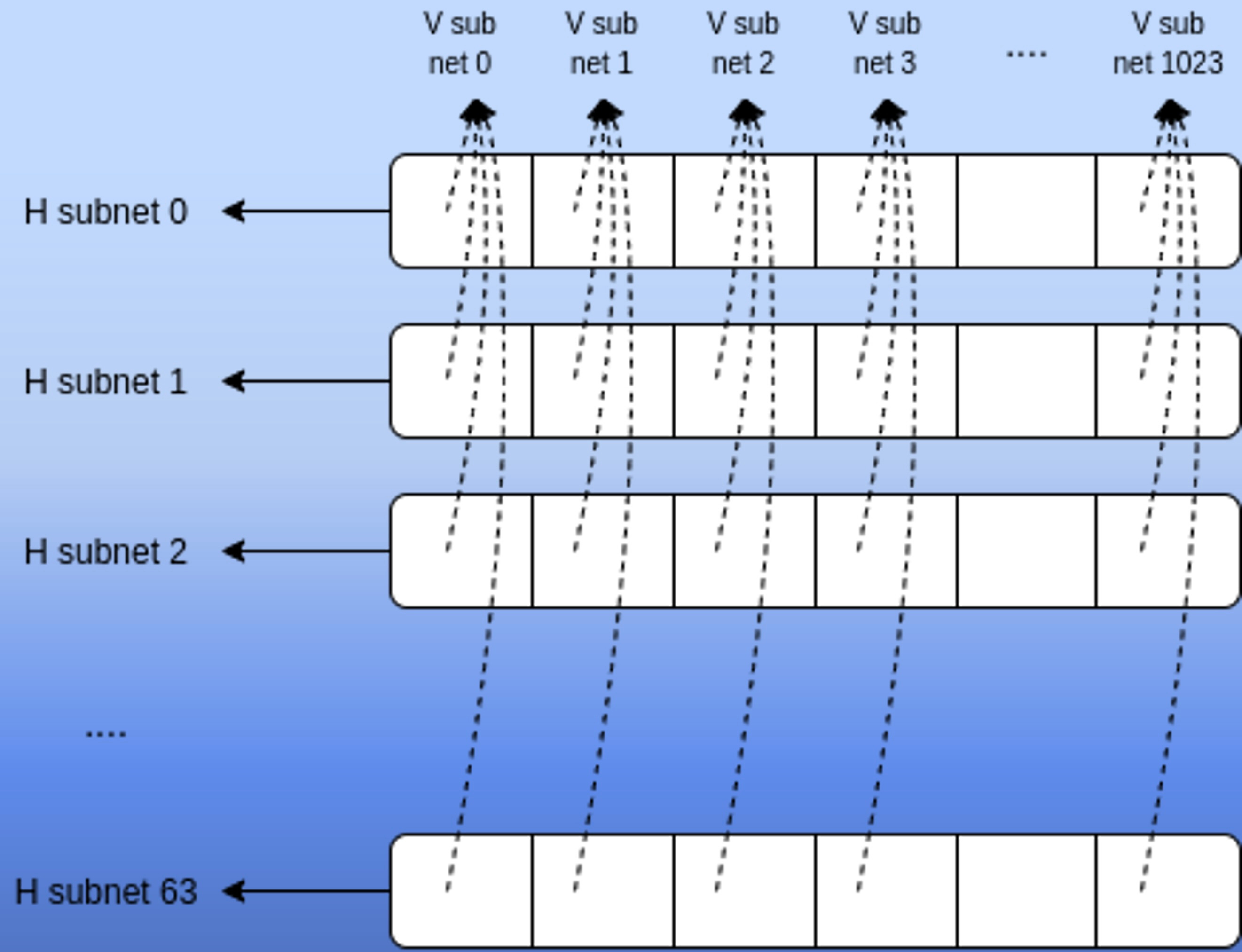
Then the network can fill in the columns from here. Remember the data gets extended in this 2D scheme. For example, each blob is 512 chunks, but it gets erasure coded into 1024 chunks. Then the extension also runs vertically. For example, you have say 32 blobs in the image here which then get extended vertically into 64 blobs. The polynomial commitments run both horizontally in each row as well as vertically in each column.
KZG Commitments
You’re able to fill in the columns thanks to the linearity of KZG commitments which will be used in Ethereum’s sharding design.
KZGs have linearity in commitments (com). For example, you can say that com(A) + com(B) = com(A+B).
You also have linearity in proofs. For example, if:
Qᴀ is a proof that A = some value at some coordinate z, and
Qʙ is a proof that B = some value at the same coordinate z, then
You can make a linear combination of Qᴀ and Qʙ, and that itself is a proof that the same linear combination of A and B has the right value at the same coordinate z
More formally:
Let Qᴀ prove A(z) and Qʙ prove B(z)
Then, cQᴀ + dQʙ proves (cA + dB)(z)
This linearity property is what allows the network to fill everything in. For example, if you had proofs for rows 0-31 in column 0, then you can use that to generate proofs for rows 32-63 in column 0.
Only KZGs have this commitment linearity and proof linearity (IPAs and Merkle trees including SNARK’d Merkle trees do not fulfill both of these).
For a deeper overview of Ethereum’s 2D KZG scheme, you can see my Ethereum report or Dankrad’s recent KZG talk. This research post by Vitalik also speaks to the considerations of using KZGs vs. IPAs for DAS.
The TLDR here is that KZGs have some very nice properties which allow for distributed block construction and reconstruction. You don’t need to require any one party to process all the data, extend all of it, compute all the KZG commitments, and propagate them. They can be done individually for each row and column. If this is done, we have no remaining supernode requirements, even for liveness:

Non-KZG Alternative
If we aren’t able to implement all the KZG magic, then here’s the next best option.
The first half of row commitments are just the blobs, so no problem there. Then the builder would have to provide the rest of them and some column commitments.
Then these commitments have to match. So the iᵗʰ row commitment at the jᵗʰ coordinate = the jᵗʰ column commitment at the iᵗʰ coordinate.
More formally:
The builder must provide row commitments R₁…Rₕ and column commitments C₁…C𝓌, where Rᵢ(xⱼ) = Cⱼ(xᵢ)
And the proof that the commitments are equivalent
This can be done in a distributed manner as discussed, but note it is harder to do:
KZG method described earlier - Can be done in one round. The builder just checks all the blobs then publishes. The network fills in the rows in a totally separate process which does not involve the builder.
Distributed method here - Requires at least a two-round protocol. The builder needs to be involved.
Extra Builder Services - Pre-confirmations
Ethereum block times are slow, and users like fast block times. Ethereum has made this sacrifice largely in hopes of supporting a large decentralized validator set - a tradeoff space Vitalik has written about here. But can we get the best of both worlds?
Ethereum rollup users have come to know and love these pre-confirmations. Builder innovation may be able to provide a similar service at the base layer.
For example, a builder could agree that:
If a user sends a transaction with priority fee ≥ 5, the builder immediately sends an enforceable signed message agreeing to include it.
If a user sends a transaction with priority fee ≥ 8, the builder even provides a post-state root. So the higher priority fee forces the transaction to be included in some order, allowing the user to know what the consequence of that transaction will be immediately.
If the builder doesn’t follow through on their commitment, they can be slashed.
In a future with a parallelized EVM, you could also get even more advanced with your pre-confirmations. For example, builders may be able to reorder some transactions within a block even after giving a pre-confirmation so long as the state that the users care about isn’t being changed.
Can a Distributed Builder Provide Pre-confirmations?
Yes. A distributed builder could just run some internal consensus algorithm like Tendermint with fast block times. Builders could be penalized for:
Double finality within the Tendermint mechanism
Signing a block that’s incompatible with what the Tendermint mechanism agreed to
Note that some kind of account abstraction for the final builder signing would be required to get the best security here. Threshold BLS is unattributable - this means that if builders are just BLS signing the block, we wouldn’t know who to slash if there’s an issue. Abstracted signing would address this issue.
For any builder pre-confirmation service (distributed or centralized), note that the pre-confirmation is only as good as their ability to actually build the winning block. More dominant builders with higher inclusion rates can provide a better pre-confirmation.
However, you could actually get a stronger pre-confirmation with a distributed builder in something like the EigenLayer construct at times. If the current proposer is opted into EigenLayer and you get a pre-confirmation, then your transaction must be included. You are no longer betting on the probabilistic odds of a centralized builder giving you a pre-confirmation then ultimately winning the block or not.
Advantages & Disadvantages of a Distributed Builder
Let’s say all the tech works out, and a distributed builder has thousands of participants. You even get a large % of the Ethereum validator set to opt into that EigenLayer construct offering sub-second pre-confirmations. This distributed builder has some nice competitive advantages over their centralized counterparts:
Economic security - Huge security deposits backing the pre-confirmation service
Trust - Searchers can trust this distributed builder far more than a single centralized entity
Censorship resistance - It’s harder to corrupt and control any secure distributed system vs. a single centralized operator deciding to be malicious
Centralized builders may have other advantages though, some inherent and some based on the construct of the distributed builder:
Quicker to adapt to new features - Flexibility to adapt to what the market wants is valuable, and this could be lacking in the distributed builder constructs described above. Ideally you could aggregate unique features from multiple parties into a block.
Lower latency - This is always relevant, but especially so for cross-chain MEV where searchers are even more likely to want to update their bids as the state of the world changes across domains. (They will also want this flexibility to modify bids throughout the course of the block in the first place as mentioned earlier.)
Concluding Thoughts
Ethereum is largely being designed with the worst case assumption - even if only a single builder exists, how can we best mitigate their power (e.g., ability to censor)?
However, we can (and should) simultaneously strive to avoid this worst case assumption as well. This means designing a system which does not always lead to an entrenched centralized builder. The two ideas described here offer some of the more interesting possibilities. However, they are far from an exhaustive list - other ideas are being actively explored, and should continue to be.
Additionally, this shouldn’t be taken as “the problem of exclusive orderflow magically goes away, so we don’t need to build around it anymore.” dApps must continue to innovate on mechanism design around MEV, including mitigating the need for exclusive orderflow. MEV ain’t going anywhere.
Special thanks to Vitalik Buterin, Sreeram Kannan, Robert Miller, and Stephane Gosselin for their review and input. This report would not be possible without them.